How to know if your recommendations algorithm is actually doing a good job
I led the team that built Channel 4’s recommender system for All 4 in 2016. It started out as a straightforward project. But after getting lost in a rabbit hole trying to devise a score for ‘provocativeness’ and ‘serendipity’, I learned the single most important lesson about data science.

When they work, recommender systems feel almost like magic: based on these things you like, here are some other things you might also like.
The trend towards personalisation has been a major driver behind data science’s popularity, and with good reason. Netflix claims that algorithmically-generated recommendations account for 80% of views, and improved Google News clickthrough by 38%.
You might think the hardest part about building a recommender system would be the core mathematical algorithm itself. Not so. The hardest part about building the recommender system for Channel 4’s ‘All 4’ digital platform turned out to be knowing whether we were doing a good job. Now, knowing whether you're doing a good job is pretty important in any field, but it's especially critical in machine learning.
At its core, machine learning is about building algorithms that automatically improve at a task with experience. The word ‘improve’ is critical here. In order for the mathematics to do its work, you have to be able to tell the algorithm, with a number, how well it’s doing at every moment.
So, to build a recommender system, you need to be able to put a number on how good your recommendations are.
Surely that’s a straightforward thing to create?
Naïve first attempt: Average Hit Rate
A good recommender system should suggest things you want to watch. So let’s start with a simple approach, called ‘average hit rate’ in the lyrical vernacular of the field.
Based on what you have watched recently, the algorithm has to guess what you are going to watch next. ‘Average hit rate’ measures how often it guesses right.

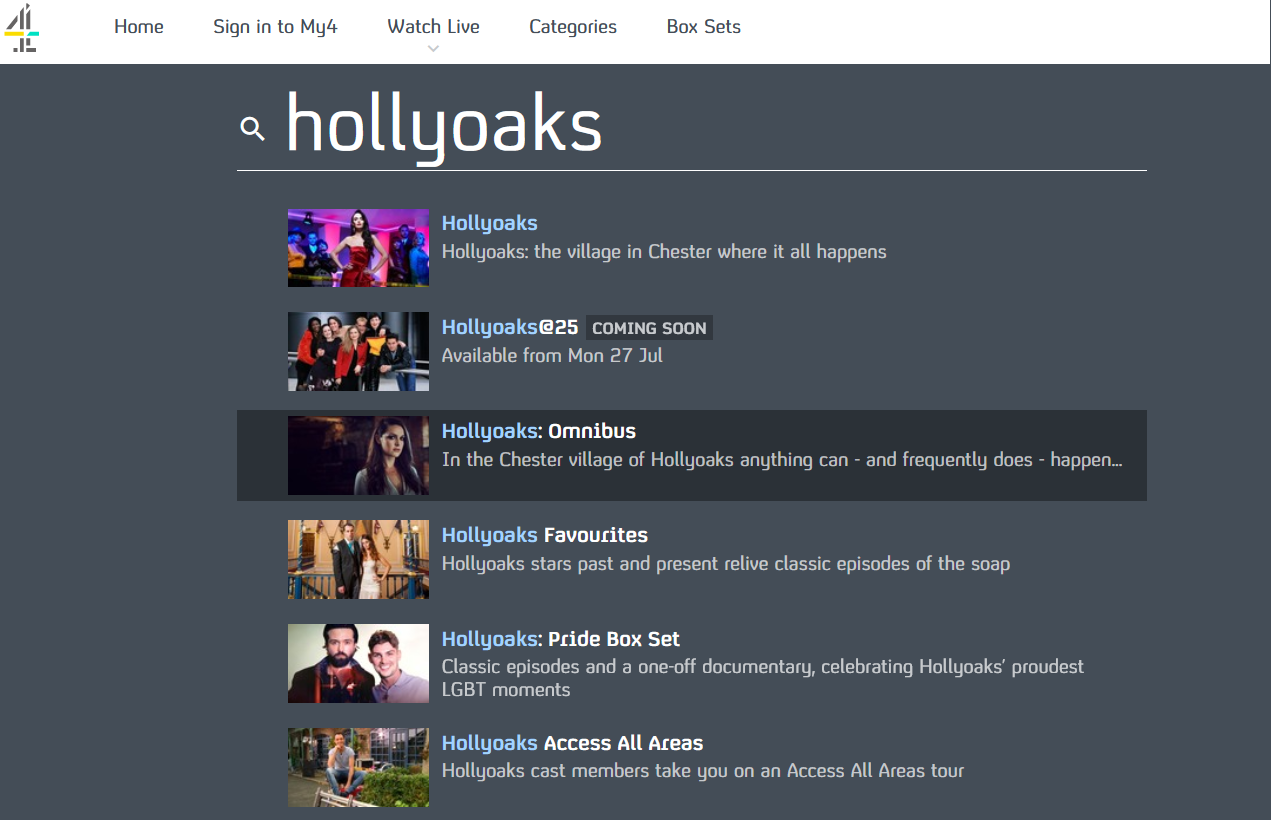
But you quickly run into problems with ‘average hit rate’. Put yourself in the shoes of a Channel 4 viewer who watched a lot of Hollyoaks (a perennially popular soap opera for teenagers). Well, we could recommend they watch ‘Hollyoaks: Best Bits 2011’, ‘Hollyoaks: Access All Areas’, and ‘Hollyoaks Does Come Dine With Me’. That would probably guess right quite a lot of the time, but it feels like it’s missing some interestingness, some serendipity, some je ne sais quoi that a really good recommendation should have.
There’s also another, more insidious problem with ‘average hit rate’: you can get a pretty good ‘average hit rate’ score by just recommending the most popular programs at the time, to everyone.
There’s no cleverness here at all, yet it ends up being right quite a lot of the time: a lot of people want (and, in our experience, went on to watch) those popular programmes, so you’ll probably be right pretty often if you guess them! But there's no personalisation and nothing relevant to a particular user. So even though it gives a better ‘average hit rate’ score than you’d imagine, that’s a failure of the metrics, rather than a success of the algorithm.
At Channel 4, this prompted some soul-searching about what makes for a really good recommendation, and how the recommender system should fit within the larger All 4 product and the Channel 4 brand.
Back to first principles: what makes a good recommendation?
A good recommendation should be relevant, certainly. That is, it should be appropriate and closely connected to your previous preferences and behaviours.
But the All 4 Product team pointed out that we also want the recommendations to be serendipitous - in other words, if we just recommend what you were already going to watch, what’s the benefit? We want to point you towards something that you would not otherwise have noticed or chosen, but turns out to be something you love.
Additionally, Channel 4 has a public service remit (defined by the UK government) to be experimental, provocative, pluralistic, educational, and distinctive. It has developed its own unique tone of voice, and its recommendations need to fit with that.

A good set of recommendations also has a kind of narrative, a cadence. You might build trust by leading with a reliable suggestion or two that are obviously relevant, then push the boat out a bit further with the next few, and end with some leftfield “Marmite” that they might either love or hate. At the very least, the set of recommendations should be a little diverse.
But not too diverse: at Channel 4 we had an embarrassing incident where the Head of Product noticed that one of our early prototypes was making completely dotty suggestions every so often - and so the data science team resolved that we wanted the algorithm to be diverse, but not laughably bad.
Lastly, there are lots of subtle (and not so subtle) ways that cultural bias or quirks in training data can introduce unwanted bias into an algorithm’s decision-making. Measuring and correcting for this bias is tricky, but should be attempted. At the very least, you might want the algorithm to be interpretable, i.e., to be able to understand why the algorithm made the suggestions it did.
Our naïve ‘average hit rate’ metric captured relevance, but it wasn’t capturing any of: serendipity, the public service remit, diversity, or not being laughably bad. If anything, by encouraging you to watch more of what you already like or stuff that’s already popular, it was doing the opposite.
But how on earth do you put a score on whether an algorithm’s recommendations are serendipitous, provocative, diverse, or laughably bad?
Average Home Run Rate
If you remember, the ‘average hit rate’ measured how often we could guess what you’d watch next, based on what you’d watched in the recent past. We modified the ‘average hit rate’ to give a higher score for correct guesses of less popular shows. In other words, the algorithm would still get a few points for guessing when someone went on to watch a really popular show, but it would get a lot more if it guessed when they went on to watch a less popular show. This will tend to produce more serendipitous recommendations.
For the public service remit (i.e., to be experimental, provocative, pluralistic, educational, distinctive etc.) and capturing the Channel 4 brand's unique tone of voice, we knew we needed to include real human experts somehow. We started with a ‘blind taste test’ experiment, comparing the results of different versions of the algorithm, and asking human experts to judge which was better.
More importantly, we designed the All 4 product so that most of the overall structure of the page was designed by human experts, restricting the algorithm’s job usually to reordering for each user, along with its own ‘Recommendations’ slot. We also gave our experts a way to highlight, blacklist and further refine the parameters of the recommendations. This balanced the importance of expert human judgment with individual-level relevance and personalisation.
Additionally, we wanted to avoid any more embarrassing incidents where we discovered too late that the algorithm was making laughably bad predictions. So we inverted the ‘average hit rate’ to create the ‘average complete miss rate’, which measured how often the algorithm completely failed to guess anything that a user watched next. We tried to minimise that!
We also introduced a rigorous quality assurance (QA) step, where human beings hunted for egregious nonsense by eye.
Taken together, this richer, blended approach to evaluating the algorithm’s performance led to a balanced recommender system that was more valuable to the user and to the business.
Don’t get lost down the rabbit hole
All 4’s recommendation algorithm started out as what I believed to be a straightforward project. But after getting lost in a rabbit hole trying to devise a score for provocativeness and serendipity, I learnt the single most important lesson about data science: if you only get one thing right as a data scientist, make sure the scoring system for your algorithm really captures what matters for the end-user and for the business.
It’s so tempting to just pick a standard, simple metric (e.g., ‘average hit rate’) and focus all your efforts on the algorithm itself. But you may end up with an algorithm that doesn’t quite behave the way you expect it to. Or worse still, it behaves how you (the data scientist) expect, but doesn’t deliver on what matters to the end-user and business.